Schlagwort: Online-Publikationen
Volltextrecherche im Internet Archive mit Open Library
Open Library ist “ein Projekt zur kollaborativen Erstellung einer auf einer bibliographischen Datenbank basierenden Online-Bibliothek. Selbsterklärtes Ziel der Open Library ist es, eine eigene Webseite für jedes bislang veröffentlichte Buch zu schaffen. In vielen Fällen wird dabei über den bibliographischen Nachweis hinaus auch der Zugang zum Digitalisat des jeweiligen Buchtitels mit hinterlegtem Volltext ermöglicht.” (Wikipedia: Open Library)
Als Teilprojekt des Internet Archive eignet sich Open Library dabei auch für die Suche in den dort enthaltenen Beständen. Unter der Rubrik “Digitale Medien” kann nun auch über den Karlsruher Virtuellen Katalog (KVK) im Internet Archive gesucht werden (Klaus Graf in Archivalia).
In einem früheren Beitrag habe ich bereits vorgestellt, wie mit dem Site:-Operator per Google-Suche auf die Volltexte im Internet Archive zugegriffen werden kann. Wikisource liefert hier eine gut durchdachte Variante:
site:archive.org/stream/ filetype:txt *
(Das Sternchen * im Eingabefeld muss dann nur durch den gewünschten Suchbegriff ersetzt und die Suche gestartet werden.)
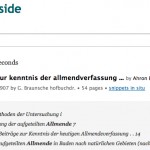
Klaus Graf macht in Archivalia auf die Volltextsuche der Open Library aufmerksam. Diese möchte ich anhand des Suchbegriffs “Allmende” vorstellen und lasse nach diesem suchen. Es erscheint eine Trefferliste mit der Kurzfassung der bibliographischen Angaben jedes gefundenen Werkes:
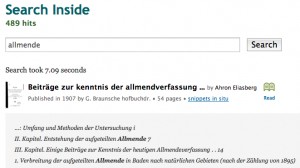
Im folgenden verwende ich “Beiträge zur kenntnis der allmendverfassung” von “Ahron Eliasberg” als Beispiel. Mit einem Mausklick auf den Namen des Werkes oder Autors gelangt man zu den jeweiligen Datensätzen der Open Library. Unter den bibliographischen Angaben der Suchtreffer werden ausgewählte Fundstellen mit dem hervorgehobenen Suchbegriff angezeigt. Zwar erscheint über der Liste die Anzahl aller ermittelten Treffer, aber leider keine Anzahl der Treffer innerhalb eines bestimmten Werkes. Die hier angezeigten Fundstellen sind nicht vollständig, erst die Funktion “snippets in situ” zeigt die einzelnen Treffer im Originalkontext:

“beitrgezurkennt00eliagoog” ist der Identifier des Items im Internet Archive, mit dem die Links zu den Metadaten und in diesem Fall zum Volltext gebildet werden:
https://archive.org/details/beitrgezurkennt00eliagoog
Der “Read”-Button mit dem Buchsymbol führt direkt zum Online-Reader des Internet Archive. Auf der Leiste zum Blättern erscheinen nun Lesezeichen für die Fundstellen im geöffneten Volltext:

Mit den Lesezeichen lassen sich nicht nur die einzelnen Seiten mit den Fundstellen gezielt aufrufen, sondern sie ermöglichen eine Vorschau auf die jeweilige Seite, die aber nicht vollständig ist.
Blättert man durch die Seiten im Volltext, werden die gefundenen Wörter farbig unterlegt angezeigt. Durch die hier vorgestellten Funktionen ist diese Suche zur Orientierung überaus praktisch, doch nach wie vor gilt Klaus Grafs Kommentar:
Jedes beim Internet Archive hochgeladene Buch erhält eine OCR, die bei Frakturschriften nach wie vor unbrauchbar ist und bei Antiquaschriften in der Regel auch nicht besonders gut. Dieser E-Text wird häufig von der Google-Websuche erfasst.
Für dieses Problem gibt es in Wikisource ein paar Suchtipps. Nach einigen Probeläufen halte ich die Suche mit dem Site:-Operator von Google nach wie vor für ergiebiger.
Wer archiviert das Internet? Eine Diskussion auf der re:publica 2014
Wer archiviert das Internet? So lautete der Titel einer Diskussion auf der re:publica 2014. Paul Klimpel (http://www.collaboratory.de), Alexis Rossi (http://archive.org) und Elisabeth Niggemann (Generaldirektorin der Deutschen Nationalbibliothek) diskutierten hierzu am Mittwoch, den 7. Mai auf der re:publica 2014. Hier die Kurzthese zur Diskussion und dem Video hierzu:
Trau, schau, wem: Kulturelle Gedächtniskonzepte jenseits der NSA Im Zuge der NSA-Enthüllungen entstand der Eindruck, Geheimdienste sammeln alles, speichern alles und archivieren alles, was an digitalen Informationen verfügbar ist. Während die Praxis der Geheimdienste im Verborgenen stattfindet, agieren Gedächtnisinstitutionen wie Bibliotheken, Archive und Museen öffentlich und unterliegen Regeln und institutionellen Zuschreibungen. Doch auch nicht-staatliche Institutionen wie das Internet Archive archivieren digitale Daten in frei zugänglicher Form. Wie unterscheiden sich Konzepte, Rahmenbedingungen und Praxis, wo gibt es Überschneidungen, wo Abgrenzungen, wo Lücken?
Recherche im Internet Archive
Das Internet Archive orientiert sich an der Vision, die Gesamtheit des menschlichen Wissens allen verfügbar zu machen. Schon jetzt hat diese Vision zu bemerkenswerten Resultaten geführt. Losgelöst von der kreativen Energie, zu der diese Vision beflügelt, bleibt besonders zu klären, welcher Wissensbegriff diesem utopischen Entwurf unterliegt.
Persönlich bin ich ein großer Fan dieses Projektes und stöbere gerne ausgiebig in den digitalen Beständen. Besonders gefällt mir dabei, dass neben der Erstellung und Pflege digitaler Bestände mit der Eröffnung der physischen Sektion ebenfalls Sorge für die Erhaltung des gedruckten Buches als Kulturgut getragen wird.
Nun möchte ich kurz skizzieren, wie ich Google für die Recherche in den Beständen des Internet Archive nutze. Damit meine ich besonders die Volltext-Recherche. Google erlaubt es, die Suche auf einzelne Internetseiten zu begrenzen. Suchen möchte ich nach dem Zitat von Walter Benjamin über die Kartothek eines Wissenschaftlers, gebe also bei Google ein:
kartothek site:archive.org
“Kartothek” ist hier mein Stichwort, “site:archive.org” begrenzt die Suche auf die entsprechende Internetseite. Nun erscheint eine Trefferliste, bei der die gelisteten Fundstellen mit “Full text of” beginnen. Dies sind natürlich die Fundstellen in den Volltexten. Ich klicke mit der Maus auf “Full text of “Einbahnstraße” – Internet Archive”, weil ich weiß, dass “Einbahnstraße” ein berühmtes Werk von Benjamin ist.
Mit dem Link gelange ich zum Volltext des Textes und kann mit meinem Browser innerhalb des Textes nach dem Stichwort “Kartothek” suchen: Vier Treffer werden angezeigt, und die Suchfunktion meines Browsers bringt mich zum gesuchten Zitat und seinem Kontext, durch die Zeichenerkennung etwas entstellt:
(Und beute scbon ist das Buch, wie die aktuelle wissen-
scbaftlicbe Produktionsweise lehrt, eine veraltete Vermitt-
lung zwischen zwei verscbiedenen Kartothekssystemen.
Denn alles Wesentlicbe findet sich im Zettelkasten des
Forscbers, der’s verfaBte, und der Gelebrte, der darin
studiert, assimiliert es seiner eigenen Kartothek.)
Die Überschrift des Textes heißt hier: “YEREIDIQTEH BUCHERREVISOR”. Etwas weiter oben im Volltext findet sich die Seitenangabe: 26. Ganz oben über dem Volltext findet sich die Überschrift “Full text of “Einbahnstraße”” mit dem Link zum Archiveintrag. Nun kann man auf der linken Seite “Read Online” wählen und im Reader zur Seite 26 Blättern. Die Seitenzahl bringt mich in die Nähe des Textes, wenige Seiten später treffe ich – durch die Überschrift – auf die gesuchte Stelle. Nun habe ich die bibliographischen Angaben zum gesuchten Zitat sowie einen direkten Link für Belege in digitalen Publikationen:
http://archive.org/stream/Einbahnstrae/BenjaminEinbahnstrae#page/n25/mode/2up
Hier ist die doppelseitige Ansicht ausgewählt.
Mit Hilfe von Google lassen sich so viele Treffer ermitteln, besonders was die Suche nach unselbständigen Publikationen oder besonderen Stichworten (Ortsnamen, veraltete Ausdrücke) betrifft. Aber aufgrund der Qualität der Scans und der Volltexte sollten die Suchabfragen stark variiert werden.
Die Möglichkeit direkter Links zu digitalisierten Quellen stellt einen bisher kaum gehobenen Schatz dar. Klaus Graf nutzt diese Möglichkeit direkter Online-Belege – hier ein Beispiel – in dem von ihm administrierten Gemeinschafts-Blog Archivalia.
Hugh McGuire (TEDxMontreal): “The Blurring Line Between Books and the Internet”
Hugh McGuire hat in den letzten Jahren viel über neue Buchpublikationsmodelle geforscht. McGuire macht in dem folgenden Vortrag anhand verschiedener Argumente deutlich, weshalb Bücher und das Internet bald eins werden könnten. Auch das Leseverhalten wird sich weiter ändern und die Bewertung dessen, was als wertvoll und “druckenswert” erachtet wird, könnte in nächster Zeit einen Wandel erfahren.
[Leseempfehlung] Für mehr Sichtbarkeit
Eric Steinhauer hat in seiner kleinen Schrift die Relevanz des Grundrechts der Wissenschaftsfreiheit für das wissenschaftliche Publizieren und die Forderung nach Open Access näher untersucht. Dabei stellt er zwei Hauptfragen:
- Open Access – ein Thema für den Gesetzgeber?
- Die Publikationsfreiheit des Wissenschaftlers – Grundrecht oder Befindlichkeit?
Das Zweitveröffentlichungsrecht für wissenschaftliche Autoren, Grundlage für den grünen Weg des Open Access, ist derzeit Gegenstand in den aktuellen Diskussionen zum Dritten Korb der Urheberrechtsnovelle. Eine Durchsetzung dieses Rechts hieße eine starke Förderung des Open Access. Daher ist es auch von besonderer Bedeutung in Zusammenhang mit dem Grundrecht der Wissenschaftsfreiheit, welches aus Art. 5 Abs. 3 GG abgeleitet werden kann.
Auch die Frage, wie der Gesetzgeber sich in dieser Situation verhalten soll, beantwortet Steinhauer sehr deutlich:
So wenig, wie der Gesetzgeber einen Wissenschaftler zu Open Access zwingen darf, so wenig darf er Open Access verbieten. Er hat sich hier schlicht herauszuhalten.
Ganz in diesem Sinne kann man das Werk von Dr. Eric Steinhauer auch im Open Access bei INFODATA-eDepot der FH Potsdam abrufen.
Steinhauer, Eric: Das Recht auf Sichtbarkeit : Überlegungen zu Open Access und Wissenschaftsfreiheit. – Monsenstein und Vannerdat, Münster 2010 (ISBN: 978-3-86991-140-3) – Preis: 11,50 €
Quelle:
Steinhauer, Eric: Open Access und Wissenschaftsfreiheit, Mailingliste Inetbib
Zur Zukunft des Buches
O’Reilly zeigt auf seiner Konferenz, wie die Zukunft des Buches aussehen kann. Gestern ist die erste “Tools of Change for Publishing”-Konferenz:engl: (TOC) des O’Reilly-Verlages zu Ende gegangen. Schmücken konnte sich die Konferenz n unter anderem mit Wikipedia-Gründer Jimmy Wales, Bürgermedien-Pionier Dan Gillmor, Adobe-Chef Bruce Chizen sowie O’Reilly-Gründer Tim O’Reilly.
Untergangs- oder Aufbruchstimmung?
In San Jose überwog auf den ersten Blick die erstere. Wiedereinmal wurde geunkt, dass gedruckte Informationen in 15 Jahren ein Fossil sein würden.
Erinnern wir uns hier Allen Noren vom O’Reilly-Verlag präsentierte Anekdoten, bei denen es Zeitungs- wie Buchverlegern eiskalt den Rücken herunterlaufen dürfte. So erzählten ihm preisgekrönte Studenten, dass “Bücher etwas für alte Leute” seien. Eine Führungskraft habe ihren MBA-Studiengang in Yale absolviert, ohne ein einziges Buch zu kaufen. “Wenn etwas nicht bei Google zu finden war, dann gab es den Text auch nicht”, erklärte der Manager.
Diskutiert wurden auf der Konferenz neue technische Varianten des Buches, von Print-Rechner-Kombinationen bis zum immer wieder verschobenen “digitalen Papier”, bei dem Bücher Hyperlinks besitzen können.
Das so genannte blueBook:engl: , das auf der TOC als Prototyp gezeigt wurde, besitzt eine solche Funktion.
Quelle:
O’Reilly-Konferenz zur Zukunft der Print-Branche via heise online
Mehr zur TOC in einem ausführlichen Konferenzbereicht in Technology Review online: Das Ende des Buchs ist seine Zukunft
Mit der Diskussion, ob die Bücher irgendwann durch das Internet ersetzt werden können und damit auch Bibliotheken, müssen sich Bibliotheken bereits länger auseinander setzen. Natürlich gibt es Bereiche, wo sich abzeichnet, dass das elektronische Medium dem gedruckten einige Vorteile gegenüber hat. Recherchefunktionalitäten, Verlinkungen, Aktualität und Schnelligkeit bei der Verfügbarkeit.
Und gibt es wirklich schon alles im Internet, so dass der Weg in die Bibliothek gespart werden kann, wo ja in der Regel das gedruckte Wort gehortet wird? Die
10 Gründe warum das Internet eine Bibliothek nicht ersetzen kann nennt Mark Y. Herring (übersetzt von Sabine Buroh) bereits 2002. Ich denke, die Argumente haben kaum an Aktualität verloren.
Und gibt es wirklich schon alles im Internet, so dass der Weg in die Bibliothek gespart werden kann, wo ja in der Regel das gedruckte Wort gehortet wird? Die
10 Gründe warum das Internet eine Bibliothek nicht ersetzen kann nennt Mark Y. Herring (übersetzt von Sabine Buroh) bereits 2002. Ich denke, die Argumente haben kaum an Aktualität verloren.
Bundesrat: Skepsis gegenüber Open Access
Die Fachgremien des Bundesrates können durch die Mitteilung der EU-Kommission über wissenschaftliche Informationen im Digitalzeitalter nicht zufriedengestellt werden. Sie bleiben zwei bei der Forderung nach einem möglichst freien, sofortigen und offenen Zugang zu Informationen, die der Zielsetzung der EU entsprechen, die europäische Wirtschaft wettbewerbsfähiger zu machen.
Gemeinsam mit dem Rechtsauschuss betonen sie aber in den Empfehlungen für eine Stellungnahme im Plenum des Bundesrates zugleich, dass dieser Ansatz “in einem Spannungsfeld mit dem Schutz des geistigen Eigentums” stehe und die Verwertungsrechte der Verlage gefährden könne.
Bei den Verwertungsrechten der Verlage handlt es sich auch um ein anderes Kriterium für den Erfolg des Binnenmarkts und die Förderung von Innovation und kreativem Schaffen.
Was wissenschaftliche Artikel anbelangt, so “beobachtet die Kommission Experimente mit Open-Access-Veröffentlichungen und zieht solche in Betracht.” Beim “Open Access”-Modell geht es um die zeitnahe Publikation von Forschungsergebnissen in speziellen Online-Archiven ohne Kosten für die Nutzung durch die Allgemeinheit.
Ein großer Kritikpunkt an Open Access ist auf Seiten des Gremiums die Tatsache, dass die
Verlage und speziell die von ihnen herausgegebenen wissenschaftlichen Zeitschriften eine zentrale Rolle im wissenschaftlichen Informationssystem einnehmen und die Verlagswirtschaft gerade in den letzten Jahren erhebliche Investitionen im Bereich Online-Publishing getätigt habe. Sie würden damit bereits zu einer effizienteren Informationsverbreitung beigetragen.
Die Verlage stünden dabei in ständigem Wettbewerb um Autoren und Leser, was letztlich die hohe Qualität der wissenschaftlichen Veröffentlichungen sicherstelle. Einig sind sich die Fachgremien, dass Open-Access-Veröffentlichungen allein einen “ergänzenden Weg der Wissensvermittlung” bei Forschungsergebnissen darstellen könnten.
Quelle:
Krempl, Stefan: Skepsis im Bundesrat gegenüber Open-Access-Publikationen via heise online