#bibtag21 – Mitschrift zu Beyond Discovery
Disclaimer: Dies ist eine Mitschrift. Sie ist weder vollständig noch sind die Informationen von mir zusammengestellt, sondern nur während der folgend genannten Veranstaltung von mir mitgeschrieben und zeitnah ohne Überarbeitung hier veröffentlicht worden.
Abstract Text: Discovery Systeme sind in der Bibliothekswelt seit einigen Jahren stark etabliert. In ihrem Funktionsumfang unterscheiden sich viele dieser Bibliothekskataloge jedoch wenig von der Kernkompetenz „alter“ OPAC-Katalogsysteme: der Recherche und dem Zugang zum eigenen Bestand. Unbestritten bleibt dies deren Hauptaufgabe. Leider haben Nutzende selten die Möglichkeit, weiterführende Zusammenhänge im Bestand bzw. darüber hinaus herzustellen. Auch der „one to rule them all“-Suchschlitz macht es den Nutzenden schwer, sich die Bestände in einer intuitiven Weise zugänglich zu machen. Im Zeitalter von Normdaten, (Linked) Open Data, Knowledge Graphen bzw. Open Source liegen viele der notwendigen Werkzeuge auf dem Tisch. Woran liegt es also, dass Bibliothekskataloge selten alternative und explorative Suchansätze anbieten?
https://dbt2021.abstractserver.com/program/#/details/presentations/97
Die Vortragenden möchten den im EFRE-Projekt „Linked Open Data“ von der SLUB Dresden entwickelten explorativen Suchansatz vorstellen und praxisnahe Einblicke in dessen Konzeptions- und Entwicklungsphasen geben. Welche Rolle spielen maschinelle Verfahren, Konkordanzen bzw. gut gepflegte Vokabularien/Thesauri zur Aufbereitung der Daten? Warum ist eine strukturierte und intellektuelle Erschließung von Beständen auch heute dabei unerlässlich? Welche Herausforderung gibt es bei der Datenvisualisierung und der Umsetzung des Suchinterfaces? Warum ist die enge Zusammenarbeit zwischen Bibliothekaren*innen, Spezialisten*innen, Informatikern*innen bzw. Designer*innen wichtig?
Mirko Clemente ist ein freiberuflicher Designer. Er hat sich auf webbasierte Datenvisualisierungen netzwerkartiger Daten wie Wissensstrukturen und Klassifizierung spezialisiert und bereits einige Projekte im bibliothekarischen Umfeld realisiert.
Jens Nauber und Tom Schilling (SLUB Dresden) befassen sich mit der Strukturierung, Bereitstellung und maschinellen Aufbereitung bibliografischer Metadaten für unterschiedliche Informationssysteme, wie der Linked Open Data API und dem Katalog der SLUB.
IST-Zustand
auch mit Blick auf die Suche der SLUB
- Es geht um die Entwicklung neuer Suchoberflächen, explorative Sucheinstiege
- Analyse: Suchschlitz immer noch zentraler Sucheinstieg + Fascetten – sehr klassisches Paradigma, zumal auch durch Google derzeit bekannt
- Smarte Bedienelemente derzeit : Vorschlagssuche, Index-Browsing, domainspezifisches Suchen -> richtige Exploration nicht möglich
Datenvisualisierung
- Datenvisualisierung ausgewählter Datensammlungen, aber ansonsten exploratives wenig zu sehen
- Es geht darum Daten zu verstehen – zugrundeliegend Titel- und Normdaten
- Eigenheiten und Schwächen mussten verstanden werden (Mikro- und Makroperspektive)
- Auswertung automatisiert und manuelle Betrachtung der Datenfelder
- wie gut sind die abgedeckt
- wie sind die Werte verteilt
- sind Muster/Zusammenhänge erkennbar
- gibt es Annomalien
- gibt es Schnittstellen
- Auch die gesamte Struktur der Linked Data muss verstanden werde
- was ist prinzipiell verknüpfbar und wie fest sind die miteinander verknüpft
- Daraus wurde der Projektfokus gestärkt
- Titeldaten Mittelpunkt und engverbundene Normdaten (Themen und Personen)
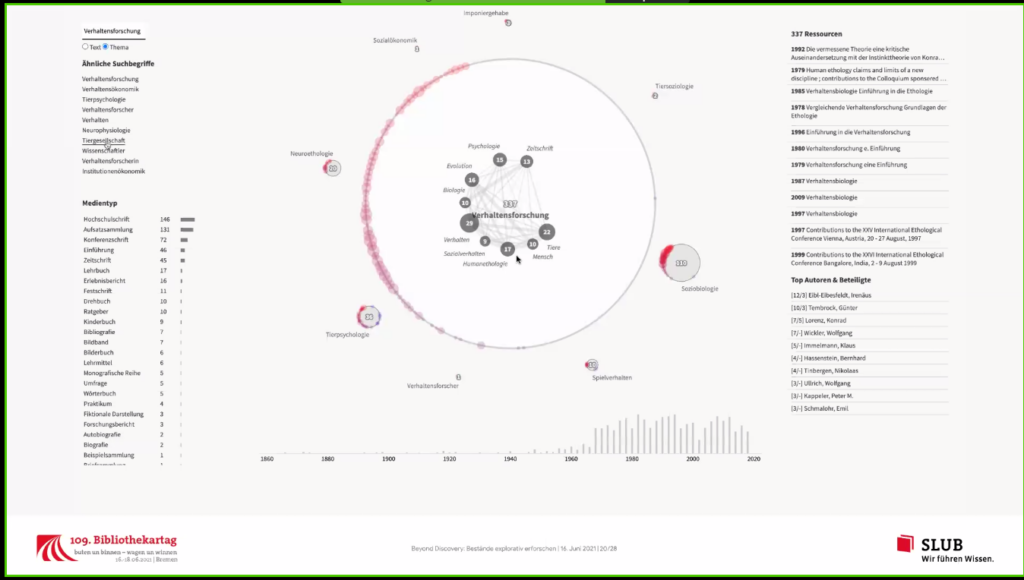
- Themen sind nicht nur Bezeichnung, sondern bestehen aus zusätzlichen Inhalten (Beschreibungen) -> vorgelagerte Suche ergibt eine Themenliste
- Das eindeutigste Thema wird im Fokus der Darstellung dargestellt, dazu werden Titeldaten und weitere Themen angezeigt
- Verwandte Themen werden auch angezeigt, nach Häufigkeit gemeinsam gefundener Inhalte
- Kontext zeigt alternative Ergebnisse (vorgelagerte Suche) -> Navigation im horizontalen Sinne
- Kontext nicht nur nach Datenlage nicht nur Verlagerung sondern auch Spezifizierung (vertikale Suchbewegung)
- Zusätzliche Themen können als Einschränkung ausgewählt werden
- Ähnliche Suchbegriffe kommen in den Daten vor und werden mit angezeigt
- Durch Anzeige können auch Missverständnisse vermieden werden
- Zeitraum wird radial und um Uhrzeigersinn herum angezeigt, um so zu zeigen, ob das Thema historisch oder aktuell ist.
Tolle Vorstellung des Prototypen der Explorativen Suchen
Was haben sie gelernt
- Es ist möglich, solche Konzepte zu erstellen, aber es ist aufwendig
- enge Zusammenarbeit zwischen Bibliothekare, Techniker und Visualisierer (Nutzerinteraktion)
- Projekt muss danach weitergepfegt werdne können
- Datenqualität ist entscheidend (möglichst vollständig) -> ERSCHLIESSUNG muss sichergestellt werden (autmatisch, aber auch intellektuell)
- Prototypen lohnen sich, aber auf Livedaten, da sonst Änderungen im speziellen Datensatz und damit Integration in Live-System
Fragen
- Wann kann man es nutzen?
- Noch Work in Progress – Alles OpenSource, aber Adaption schwierig – für SLUB-Katalog soll es adaptiert werden als Ergänzung zu Suchparadigma
- Für das Produkt wird es noch dauern, aber der Prototyp wird abgekapselt vermutl. in den nächsten Monaten in den data.slub-dresden.de veröffentlicht
- Verwandtschaft entsteht dadurch, wie oft ein Thema mit einem anderen auftritt (hier wird noch expermimentiert)
- Usability-Test mit Bibliotekarinnen, Nutzerinnen geplant
- Heterogene Daten sind großes Problem insbesondere für Erschließung
- thematisch 69% erschlossen, aber oft nicht gut erschlossen, für Prototyp Goldstandard – Daten aus dem Verbundkatalog
Mein Fazit: Das ist eine Entwicklung, auf die ich mich sehr freue und die hoffentlich in den nächsten Jahren zu einer Marktreife gebracht werden wird.

