Linked Data Mapping Cultures
Eine interessante Präsentation:
Bibliothekarisch – die berufliche Tätigkeit eine:r Bibliothekar:in betreffend.
Eine interessante Präsentation:
Gastbeitrag von Sabine Wolf, Projektkoordinatorin Weiterbildung – Bibliotheksmanagement an der Fachhochschule Potsdam
Wie passt das denn zusammen? Wir finden gut! Darum erforschen wir auch seit Anfang Juni im Rahmen des „MylibrARy“-Projektes welche Anwendungsszenarien in Bibliotheken Sinn machen. Ziel ist es, eine App zu entwickeln, die bundesweit eingesetzt werden kann.
Im Rahmen des BMWE-Förderprogramms ZIM-Koop kooperiert der Fachbereich Informationswissenschaften der FH Potsdam mit einer der führenden Augmented Reality-Firmen, der metaio GmbH aus München. Weitere Partner sind die Egon-Erwin-Kisch-Bibliothek Berlin-Lichtenberg und der VÖBB Berlin.
Zurzeit findet gerade eine von uns initiierte eine Umfrage unter Bibliotheken und Bibliotheksnutzern statt, die das Ziel verfolgt, herauszufinden, welche Funktionalitäten die App haben sollte. Als Antworten kamen neben den Klassikern wie „Kontoabfrage“ und „Standort-Funktion“ auch Vorschläge wie „Bibliotheksquiz“ oder „Wer liest was ähnliches wie ich“. Insgesamt wird die Umfrage sehr gut angenommen und die bisherigen Ideen zeigen, wie offen das Thema aufgenommen wird.
Einige der gemachten Vorschläge werden bereits für die erste Testversion umgesetzt werden können. So z.B. die Social Media- und die Rating-Funktion. Im Rahmen eines Projekttreffens mit metaio Mitte November wird die Umsetzung weiterer Vorschläge ein zentrales Thema sein.
Die Umfrage läuft noch bis zum 9. November und wir freuen uns über weitere Vorschläge! Zur Umfrage geht es hier.
Mehr Infos zum Projekt findet Ihr unter http://mylibrary.fh-potsdam.de/
In dem Artikel “Auf in die Zukunft! Was kommt nach der bücherlosen Bibliothek?“, der dieses Jahr in der Zeitschrift Libreas erschien, wurde bereits auf den Internetsoziologen Stephan Humer verwiesen, der darauf aufmerksam machte, dass bei der Nutzung eines E-Books das Leseverhalten überwacht wird. Sind wir bereits gläserne Leser und den Konzernen wie Amazon, Apple und anderen Ebookherstellern hilflos ausgeliefert? Werden sich Verlage und Autoren künftig anhand markierter Textstellen und gelesener Kapitel danach richten, was der Leser für wichtig erachtet und sich dem an den Massengeschmack anbiedern? Kann dadurch der Erfolg eines Autors im Vorhinein gemessen bzw. im Voraus kalkuliert werden?
Ihr kennt die Jungs und Mädels schon als Macher von den Videos “If Google was a guy”. Diesmal nehmen sie sich einem ernsten Thema an und erklären uns, warum Netzneutralität wichtig ist.
Im Grundstudium an der Fachhochschule Potsdam lernten wir als Studenten die Ursprünge des World Wide Web ausführlich kennen. Im folgenden Video werden die Entstehungshintergründe auf spannende und interessante Weise erläutert. Die Videomacher sind ein Team aus Designern in München, die sich über künftige Themenvorschläge auf deren einschlägigen Social Media Seiten freuen.

Unsere Welt wird digitaler. Das DIGITAL AGENDA SCOREBOARD 2014 zeigt, dass die Kommission Digital Agenda for Europe (DAE) über 100 Punkte aktiv umsetzen will bis 2015.
Für Bibliotheken von besonderem Interesse sind “Internet Use, Digital Skills and Online Content“.
Open Library ist “ein Projekt zur kollaborativen Erstellung einer auf einer bibliographischen Datenbank basierenden Online-Bibliothek. Selbsterklärtes Ziel der Open Library ist es, eine eigene Webseite für jedes bislang veröffentlichte Buch zu schaffen. In vielen Fällen wird dabei über den bibliographischen Nachweis hinaus auch der Zugang zum Digitalisat des jeweiligen Buchtitels mit hinterlegtem Volltext ermöglicht.” (Wikipedia: Open Library)
Als Teilprojekt des Internet Archive eignet sich Open Library dabei auch für die Suche in den dort enthaltenen Beständen. Unter der Rubrik “Digitale Medien” kann nun auch über den Karlsruher Virtuellen Katalog (KVK) im Internet Archive gesucht werden (Klaus Graf in Archivalia).
In einem früheren Beitrag habe ich bereits vorgestellt, wie mit dem Site:-Operator per Google-Suche auf die Volltexte im Internet Archive zugegriffen werden kann. Wikisource liefert hier eine gut durchdachte Variante:
site:archive.org/stream/ filetype:txt *
(Das Sternchen * im Eingabefeld muss dann nur durch den gewünschten Suchbegriff ersetzt und die Suche gestartet werden.)
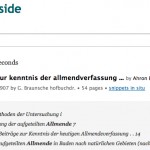
Klaus Graf macht in Archivalia auf die Volltextsuche der Open Library aufmerksam. Diese möchte ich anhand des Suchbegriffs “Allmende” vorstellen und lasse nach diesem suchen. Es erscheint eine Trefferliste mit der Kurzfassung der bibliographischen Angaben jedes gefundenen Werkes:
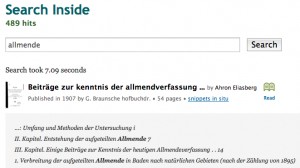
Im folgenden verwende ich “Beiträge zur kenntnis der allmendverfassung” von “Ahron Eliasberg” als Beispiel. Mit einem Mausklick auf den Namen des Werkes oder Autors gelangt man zu den jeweiligen Datensätzen der Open Library. Unter den bibliographischen Angaben der Suchtreffer werden ausgewählte Fundstellen mit dem hervorgehobenen Suchbegriff angezeigt. Zwar erscheint über der Liste die Anzahl aller ermittelten Treffer, aber leider keine Anzahl der Treffer innerhalb eines bestimmten Werkes. Die hier angezeigten Fundstellen sind nicht vollständig, erst die Funktion “snippets in situ” zeigt die einzelnen Treffer im Originalkontext:

“beitrgezurkennt00eliagoog” ist der Identifier des Items im Internet Archive, mit dem die Links zu den Metadaten und in diesem Fall zum Volltext gebildet werden:
https://archive.org/details/beitrgezurkennt00eliagoog
Der “Read”-Button mit dem Buchsymbol führt direkt zum Online-Reader des Internet Archive. Auf der Leiste zum Blättern erscheinen nun Lesezeichen für die Fundstellen im geöffneten Volltext:

Mit den Lesezeichen lassen sich nicht nur die einzelnen Seiten mit den Fundstellen gezielt aufrufen, sondern sie ermöglichen eine Vorschau auf die jeweilige Seite, die aber nicht vollständig ist.
Blättert man durch die Seiten im Volltext, werden die gefundenen Wörter farbig unterlegt angezeigt. Durch die hier vorgestellten Funktionen ist diese Suche zur Orientierung überaus praktisch, doch nach wie vor gilt Klaus Grafs Kommentar:
Jedes beim Internet Archive hochgeladene Buch erhält eine OCR, die bei Frakturschriften nach wie vor unbrauchbar ist und bei Antiquaschriften in der Regel auch nicht besonders gut. Dieser E-Text wird häufig von der Google-Websuche erfasst.
Für dieses Problem gibt es in Wikisource ein paar Suchtipps. Nach einigen Probeläufen halte ich die Suche mit dem Site:-Operator von Google nach wie vor für ergiebiger.