Linked Data Mapping Cultures
Eine interessante Präsentation:
Bibliothekarisch – die berufliche Tätigkeit eine:r Bibliothekar:in betreffend.
Eine interessante Präsentation:
Open Library ist „ein Projekt zur kollaborativen Erstellung einer auf einer bibliographischen Datenbank basierenden Online-Bibliothek. Selbsterklärtes Ziel der Open Library ist es, eine eigene Webseite für jedes bislang veröffentlichte Buch zu schaffen. In vielen Fällen wird dabei über den bibliographischen Nachweis hinaus auch der Zugang zum Digitalisat des jeweiligen Buchtitels mit hinterlegtem Volltext ermöglicht.“ (Wikipedia: Open Library)
Als Teilprojekt des Internet Archive eignet sich Open Library dabei auch für die Suche in den dort enthaltenen Beständen. Unter der Rubrik „Digitale Medien“ kann nun auch über den Karlsruher Virtuellen Katalog (KVK) im Internet Archive gesucht werden (Klaus Graf in Archivalia).
In einem früheren Beitrag habe ich bereits vorgestellt, wie mit dem Site:-Operator per Google-Suche auf die Volltexte im Internet Archive zugegriffen werden kann. Wikisource liefert hier eine gut durchdachte Variante:
site:archive.org/stream/ filetype:txt *
(Das Sternchen * im Eingabefeld muss dann nur durch den gewünschten Suchbegriff ersetzt und die Suche gestartet werden.)
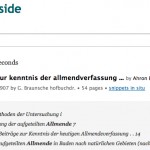
Klaus Graf macht in Archivalia auf die Volltextsuche der Open Library aufmerksam. Diese möchte ich anhand des Suchbegriffs „Allmende“ vorstellen und lasse nach diesem suchen. Es erscheint eine Trefferliste mit der Kurzfassung der bibliographischen Angaben jedes gefundenen Werkes:
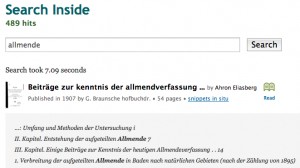
Im folgenden verwende ich „Beiträge zur kenntnis der allmendverfassung“ von „Ahron Eliasberg“ als Beispiel. Mit einem Mausklick auf den Namen des Werkes oder Autors gelangt man zu den jeweiligen Datensätzen der Open Library. Unter den bibliographischen Angaben der Suchtreffer werden ausgewählte Fundstellen mit dem hervorgehobenen Suchbegriff angezeigt. Zwar erscheint über der Liste die Anzahl aller ermittelten Treffer, aber leider keine Anzahl der Treffer innerhalb eines bestimmten Werkes. Die hier angezeigten Fundstellen sind nicht vollständig, erst die Funktion „snippets in situ“ zeigt die einzelnen Treffer im Originalkontext:

„beitrgezurkennt00eliagoog“ ist der Identifier des Items im Internet Archive, mit dem die Links zu den Metadaten und in diesem Fall zum Volltext gebildet werden:
https://archive.org/details/beitrgezurkennt00eliagoog
Der „Read“-Button mit dem Buchsymbol führt direkt zum Online-Reader des Internet Archive. Auf der Leiste zum Blättern erscheinen nun Lesezeichen für die Fundstellen im geöffneten Volltext:

Mit den Lesezeichen lassen sich nicht nur die einzelnen Seiten mit den Fundstellen gezielt aufrufen, sondern sie ermöglichen eine Vorschau auf die jeweilige Seite, die aber nicht vollständig ist.
Blättert man durch die Seiten im Volltext, werden die gefundenen Wörter farbig unterlegt angezeigt. Durch die hier vorgestellten Funktionen ist diese Suche zur Orientierung überaus praktisch, doch nach wie vor gilt Klaus Grafs Kommentar:
Jedes beim Internet Archive hochgeladene Buch erhält eine OCR, die bei Frakturschriften nach wie vor unbrauchbar ist und bei Antiquaschriften in der Regel auch nicht besonders gut. Dieser E-Text wird häufig von der Google-Websuche erfasst.
Für dieses Problem gibt es in Wikisource ein paar Suchtipps. Nach einigen Probeläufen halte ich die Suche mit dem Site:-Operator von Google nach wie vor für ergiebiger.
… an Katzen
Ich bin auf Twitter über zwei Accounts gestolpert, die auf Katzenbilder verlinken. Und das Tolle ist, sie nutzen dafür Digitale Bibliotheken.
Vorbild ist der Twitteraccount Historical Cats (@HistoricalCats), welches zufällige Bilder mit Katzen von der Digital Public Library of America verlinkt.
Meow! "[A book of cheerful cats and other animated animals /" http://t.co/vdD5VrjHeq
— Historical Cats (@HistoricalCats) 9. Februar 2014
Tipp: Am besten wirklich mal bis zu dem im Tweet verlinkten Bilderbuch durchklicken. Es ist wirklich hinreißend.
Peter Mayr (@hatorikibble) hat diesen Bot nachgebaut. DDB Katzenbilder (@ddbKatzen) verlinkt nun zufällig ausgewwählte Bilder mit Katzen von der Deutschen Digitalen Bibliothek.
Ganz etwas originelles: 'Hungrige Katze': http://t.co/BPD3HLkOcI #ddb
— DDB Katzen (@ddbKatzen) 9. Februar 2014
Das Internet Archive orientiert sich an der Vision, die Gesamtheit des menschlichen Wissens allen verfügbar zu machen. Schon jetzt hat diese Vision zu bemerkenswerten Resultaten geführt. Losgelöst von der kreativen Energie, zu der diese Vision beflügelt, bleibt besonders zu klären, welcher Wissensbegriff diesem utopischen Entwurf unterliegt.
Persönlich bin ich ein großer Fan dieses Projektes und stöbere gerne ausgiebig in den digitalen Beständen. Besonders gefällt mir dabei, dass neben der Erstellung und Pflege digitaler Bestände mit der Eröffnung der physischen Sektion ebenfalls Sorge für die Erhaltung des gedruckten Buches als Kulturgut getragen wird.
Nun möchte ich kurz skizzieren, wie ich Google für die Recherche in den Beständen des Internet Archive nutze. Damit meine ich besonders die Volltext-Recherche. Google erlaubt es, die Suche auf einzelne Internetseiten zu begrenzen. Suchen möchte ich nach dem Zitat von Walter Benjamin über die Kartothek eines Wissenschaftlers, gebe also bei Google ein:
kartothek site:archive.org
„Kartothek“ ist hier mein Stichwort, „site:archive.org“ begrenzt die Suche auf die entsprechende Internetseite. Nun erscheint eine Trefferliste, bei der die gelisteten Fundstellen mit „Full text of“ beginnen. Dies sind natürlich die Fundstellen in den Volltexten. Ich klicke mit der Maus auf „Full text of „Einbahnstraße“ – Internet Archive“, weil ich weiß, dass „Einbahnstraße“ ein berühmtes Werk von Benjamin ist.
Mit dem Link gelange ich zum Volltext des Textes und kann mit meinem Browser innerhalb des Textes nach dem Stichwort „Kartothek“ suchen: Vier Treffer werden angezeigt, und die Suchfunktion meines Browsers bringt mich zum gesuchten Zitat und seinem Kontext, durch die Zeichenerkennung etwas entstellt:
(Und beute scbon ist das Buch, wie die aktuelle wissen-
scbaftlicbe Produktionsweise lehrt, eine veraltete Vermitt-
lung zwischen zwei verscbiedenen Kartothekssystemen.
Denn alles Wesentlicbe findet sich im Zettelkasten des
Forscbers, der’s verfaBte, und der Gelebrte, der darin
studiert, assimiliert es seiner eigenen Kartothek.)
Die Überschrift des Textes heißt hier: „YEREIDIQTEH BUCHERREVISOR“. Etwas weiter oben im Volltext findet sich die Seitenangabe: 26. Ganz oben über dem Volltext findet sich die Überschrift „Full text of „Einbahnstraße““ mit dem Link zum Archiveintrag. Nun kann man auf der linken Seite „Read Online“ wählen und im Reader zur Seite 26 Blättern. Die Seitenzahl bringt mich in die Nähe des Textes, wenige Seiten später treffe ich – durch die Überschrift – auf die gesuchte Stelle. Nun habe ich die bibliographischen Angaben zum gesuchten Zitat sowie einen direkten Link für Belege in digitalen Publikationen:
http://archive.org/stream/Einbahnstrae/BenjaminEinbahnstrae#page/n25/mode/2up
Hier ist die doppelseitige Ansicht ausgewählt.
Mit Hilfe von Google lassen sich so viele Treffer ermitteln, besonders was die Suche nach unselbständigen Publikationen oder besonderen Stichworten (Ortsnamen, veraltete Ausdrücke) betrifft. Aber aufgrund der Qualität der Scans und der Volltexte sollten die Suchabfragen stark variiert werden.
Die Möglichkeit direkter Links zu digitalisierten Quellen stellt einen bisher kaum gehobenen Schatz dar. Klaus Graf nutzt diese Möglichkeit direkter Online-Belege – hier ein Beispiel – in dem von ihm administrierten Gemeinschafts-Blog Archivalia.
Im Internet Archive werden Internetdokumente langzeitarchiviert, um auch die Geschichte des Internets und dessen Inhalte zu erhalten. Das Archive ist derzeit die weltgrößte Online-Bibliothek der Welt. In ihr sind 10 Petabytes Informationen (Bücher,Texte, Webseiten, Filme, Audios, Live-Musik, Fernsehsendungen) gespeichert. Um das Erreichen des 10-Petabyte-Meilensteins zu feiern, wurde dieses Video im Oktober 2012 während der „Books in Browsers Conference“ und der „10 Petabyte Celebration“ produziert.
Im ersten Teil des Videos sind Brewster Kahle, Gründer des Internet Archives und seine Kollegen, Robert Miller (Bücher) und Alexis Rossi (Websammlung) zu sehen. Sie erklären ihre Mission, universellen Zugang zum Wissen der Welt zu bieten. Das Video beinhaltet auch eine Tour durch das Hauptquartier des Internet Archives in San Francisco, das Scan-Zentrum für Bücher und die Buchaufbewahrung in Richmond, Karlifornien.
Internet Archive from Deepspeed media on Vimeo.
Directed by Jonathan Minard
Cinematography by John Behrens, Alexander Porter, and Fearghal O'dea
Project supported by Eyebeam
Das Portal unglue.it hat sich zum Ziel gesetzt, bereits publizierte Bücher mittels Crowdfunding als E-Books unter CC-Lizenz verfügbar zu machen:
When you buy a book, you get a copy for yourself. When you unglue it, you give a copy to yourself and everyone on earth.
Derzeit laufen auf der Plattform drei „campaigns“, haben also drei Autoren einen Preis festgelegt, der durch die Netzcommunity erreicht werden muss, damit ihr Buch als DRM-freies E-Book auf dem Portal bereitgestellt wird. Weitere Werke kann man nach Registrierung zu einer Wunschliste hinzufügen. Finden sich genügend Interessierte, kann eine campaign gestartet werde, vorausgesetzt die Rechte lassen sich klären.
Eine interessante Idee – besonders, wenn man im ZEIT ONLINE-Artikel „Unglue.it befreit Bücher“ darüber hinaus liest, dass der „Geschäftsführer Eric Hellman […] zuvor Kommunikations- und Entwicklungsplattformen für Bibliotheken [entwickelte]“. Und so verwundert es auch nicht, dass viele (amerikanische) Bibliothekarinnen und Bibliothekare unter den Unterstützern der Plattform sind. Bei den deutschen Kolleginnen und Kollegen (namentlich ekz bzw. Onleihe) scheint das Konzept laut Hänßler eher auf Skepsis zu stoßen, vor allem, was die Attraktivität der Titel angeht. Allerdings muss es m.E. ja auch nicht vorrangig um Bestseller gehen, sondern ein solches Verfahren einer nachträglichen „E-Bookisierung“ könnte z.B. auch für vergriffene Werke spannend sein (was derzeit ja durchaus schon von einigen Bibliotheken als Print-on-Demand Service (kostenpflichtig) angeboten wird, mit dem Unterschied, dass dann eben nur eine Person etwas davon hat).
Und noch ein anderer Aspekt ist spannend: die Autorinnen und Autoren bekommen durch die Resonanz auf die von ihnen festgelegte und zu finanzierende Summe eine Aussage über den realen Wert ihres Werks (denn es wurden auch schon campaigns wieder geschlossen, die nicht genügend Förderer fanden). Dies könnte natürlich auch manche Autorinnen und Autoren davon abhalten, sich dieser öffentlichen Bewertung zu stellen.
Auf jeden Fall ist es begrüßenswert, dass es (nicht nur im Bereich E-Books) zunehmend mehr Versuche gibt, unterschiedliche Geschäftsmodelle auf ihre Tragfähigkeit in der digitalen Welt zu testen und zu etablieren. Welche sich durchsetzen, werden im besten Fall letztlich die Nutzer entscheiden.
Quelle: Boris Hänßler: Unglue.it befreit Bücher, ZEIT ONLINE

Dezember 2009 berichtete ich das erste Mal über die Deutsche Digitale Bibliothek (DDB), die – hm, was bei mir ein wenig in Vergessenheit geraten ist – 2011 online gehen sollte.

Deutsche Digitale Bibliothek
Dieser Termin konnte nicht ganz gehalten werden. Wir haben 2012 und jetzt werden erste – noch recht waage – Termine geäußert.
Dagmar Giersberg schreibt in ihrem Beitrag „Traumhafte Aussichten – die Deutsche Digitale Bibliothek“ fürs Goethe-Institut:
Etwa Mitte 2012 soll die DDB – unter neuem Namen – für einen dann eventuell noch eingeschränkten Pilotbetrieb freigeschaltet werden. Beim geplanten Start werden mindestens 4 Millionen Digitalisate aus 13 einschlägigen Einrichtungen zugänglich gemacht.
Mit der DDB leistet Deutschland seinen nationalen Beitrag zur Europeana. Weiterlesen
Was haben sich Bibliotheken nicht alles vom DiviBib-Angebot Onleihe versprochen? Gern glaubte man, dass die Onleihe der Anschluss ans Internetzeitalter ist und dass nun die Bibliotheksnutzer zumindest nur so in die schöne, neue digitale Welt der Bibliotheken strömen würden. Bequem von Zuhause, 24 Stunden, 7 Tagen die Woche. Einzige Hürde sei der Bibliotheksausweis, für den man sich je nach Bibliotheksregel einmal im Jahr in die nächste Öffentliche Bibliothek begeben müsste.
Leider zeigt sich, dass dies nicht ganz so einfach ist und in Thüringen ist die Lage bei der Thüringer Internet-Bibliothek Thuebibnet drei Jahre nach Start gelinde gesagt schwierig. Annette Kasper, die Vorsitzende des Thüringer Landesverbandes im Deutschen Bibliotheksverband, äußerte sich dem MDR THÜRINGEN gegenüber zu diesem Thema. Ein leichter Anstieg bei den Online-Ausleihen lässt sich zwar verzeichnen, aber die Zahl bleibt dennoch hinter allen Erwartungen zurück. So wurden 2009 ca. 17.000 und im vergangenen Jahr rund 27.000 Ausleihen getätigt, so waren es bis Ende September des laufenden Jahres bereits etwa 24.000 Medien. Das heißt, dass wohl vermutlich bis Jahresende nicht jedes Medium in der Online-Bibliothek wenigstens einmal ausgeliehen sein wird. Derzeit werden 34.000 Medien zu Ausleihe angeboten.
Nun will man zur Belebung der recht „toten“ Bibliothek eine große Plakataktion starten. Kaspers setzt darauf, dass die Bibliothek davon profitieren wird, denn wann immer für bestimmte Zielgruppen oder ein bestimmtes Angebot geworben hatte, konnte die Bibliothek Zuwächse erreichen.
Die Zahlen sind auch unbefriedigend, legt man ihnen die Zahl der beteiligten Bibliotheken zugrunde. Es beteiligen sich die Bibliotheken von Arnstadt, Erfurt, Gotha, Greiz, Ilmenau, Jena, Meiningen, Nordhausen, Schmalkalden, Sömmerda und Zella-Mehlis. Unterstützt wird das Angebot mit 20.000 Euro pro Jahr. Ob allein eine Plakataktion ausreicht, um eine akzeptable Nutzung des Angebots zu erreichen, halte ich für fraglich. Viel mehr müssen meiner Meinung nach die Nutzungsbedingungen und das Angebot des Thuebibnet überdacht und verbessert werden.
Quelle:
Thüringer Internet-Bibliothek: Kaum Leser – Werbeaktion geplant, MDR Thüringen
Die Scannbemühungen der Staatsbibliothek Berlin nehmen Formen an. Gescannt wird für die Deutsche Digitale Bibliothek (DDB) und die Stabi ist nicht die einzige Einrichtung, die dafür tätig wird. Insgesamt soll die DDB an die 30.000 Kunst- und Wissenschaftseinrichtungen vernetzen und mehrere Millionen Digitalisate verschiedenster Medienarten in einer Datenbank zugänglich machen.
Bereits im ersten Halbjahr 2012 soll so für jeden der Zugang zu mehreren Millionen Büchern, Musikstücken, Filmen, Fotos und 3D-Objekten über den eigenen PC möglich sein. Ein erster mehrmonatiger Test soll Oktober diesen Jahres starten. Die DDB soll dann bereits zwei bis drei Millionen Objekte enthalten.
Dies ist ein hochgestecktes Ziel, denn bereits die Europeana hat gezeigt, dass die Datenbank sehr komplex sein muss, um den Anforderungen technischer Art genauso gerecht zu werden wie denen für eine gute Benutzbarkeit. Derzeit sucht man mit einer Ausschreibung Partner, die Massendigitalisierungen stämmen können. Denkbar wäre z.B. Google. Der Internetriese hat bereits weltweit ganze Bibliotheksbestände für Google Books eingescannt und kooperiert u.a. mit der British Library, wo bis 2020 ca. 14 Millionen Bücher digitalisiert und online gestellt werden sollen.
Finanziert wird der laufende Betrieb der DDB durch die Länder und den Bund mit 1,3 Millionen Euro jährlich. Pate dieses deutschen Mammutprojektes ist die Europäische Union, deren Mitgliedsstaaten sich verpflichtet haben, ihre Kulturgüter so über das Internet zugänglich zu machen. Vorbildfunktion und Start die Europeana, die Bibliotheken, Archive und Museen vernetzt und Juli 2010 bereits 10 Millionen digitale Objekte zugänglich machte. Der deutsche Anteil war sehr gering und mit der DDB wird der deutsche Beitrag zur Europeana ausgebaut.
Die Geschäftsstelle der DDB ist in der Stabi Berlin angesiedelt, für die technische Umsetzung sorgt das Fraunhofer-Institut für Intelligente Analyse- und Information. Verstärkt wird hier auf die Entwicklungen des Semantic Web gesetzt, welches Informationen interpretieren und diese in Beziehungen zu anderen Daten setzen soll. Die so entstehenden Vernetzungsoptionen des DDB-Programms sind weltweit einmalig. Der Suchende kann dann entscheiden, ob er Objekte aus, in oder über eine Stadt sehen möchte. Wird man damit Google als Konkurrenten, wenn man ihn den Internetriesen so bezeichnen will, ausstechen?
Vor wenigen Tagen erst verkündeten Google und die British Library ihre Zusammenarbeit. Gemeinsam will man urheberrechtsfreie Werke, die zwischen 1700 – 1870 erschienen sind, digitalisieren:video:. Dabei übernimmt Google die Kosten und stellt die Digitalisate auch der British Library zur Verfügung.
Quellen:
Maisch, Andreas: Die Bibliothek kommt nach Hause, Tagesspiegel
Pluta, Werner: Google scannt Bücher aus der British Library, Golem.de
Im folgenden witzigen Video wird für die neue Webportal digitale-etalages.nl geworben. Nachhaltigkeit ist eines der Schlüsselthemen der Webseite. Weitere Informationen zum Thema Essen und Kochen, zur Wissenschaft und Technologie, sowie zu Bildung und Wasser bietet diese Internetseite.